[2025년] 정보처리기사 실기 - Database
2025년도 1회, 2회, 3회의 정보처리기사 실기 기출문제 속 Database 문제를 정리하였다.
2025년 1회 정보처리기사 실기
문제 1. 관계형 데이터베이스의 무결성 제약조건
(1) 기본키(Primary Key)를 구성하는 모든 속성을 절대로 NULL값이나 중복된 값을 가질 수 없다는 규칙이다.
(2) 외래키(Foreign Key)의 값은 반드시 참조하고 있는 테이블의 기본키 값으로 존재하거나 NULL이어야 한다는 규칙이다.
(3) 특정 속성(컬럼)에 대해 미리 정의된 형식과 범위 내에서만 데이터가 입력되도록 제한하는 규칙이다.
더보기
[정답]
(1) 개체 무결성 제약조건
(2) 참조 무결성 제약조건
(3) 도메인 무결성 제약조건
[풀이]
무결성 제약 조건
데이터베이스에 들어있는 데이터의 정확성을 보장하기 위해 부정확한 자료가 데이터베이스 내에 저장되는 것을 방지하기 위한 제약조건이다.
[종류]
- 개체 무결성 제약조건
각 릴레이션의 기본키를 구성하는 속성은 NULL 값이나 중복된 값을 가질 수 없다.
즉, 기본키는 항상 유일하고 비어있을 수 없는 값이어야 한다. - 참조 무결성 제약조건
외래키 값은 NULL이거나 참조하는 릴레이션의 기본키 값과 동일해야한다.
즉, 각 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다. - 도메인 무결성 제약조건
각 속성들의 값은 정의된 도메인에 속한 값이어야 한다.ex) 나이 속성에 음수 값이나 이상한 값이 들어갈 수 없다.
성별이라는 속성에 ‘남’, ‘여’를 제외한 데이터는 제한되어야 한다. - 고유 무결성 제약조건
특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우,
릴레이션의 각 튜플이 가지는 속성 값들은 고유한 값을 가져야 한다.ex) [학생] 릴레이션에서 ‘이름’과 ‘나이’는 서로 같은 값을 가질 수 있지만,
‘학번’의 경우 각 튜플은 서로 다른 값을 가져야 한다. - NULL 무결성 제약조건
릴레이션의 특정 속성 값은 NULL이 될 수 없다.ex) 주민등록번호가 반드시 입력되어야 한다면 NULL 값은 허용되지 않는다.
- 키 무결성 제약조건
각 릴레이션은 최소한 한 개 이상의 키를 가져야 하며, 키는 튜플을 식별할 수 있는 값이어야 한다.ex) [학번] 릴레이션에서 ‘학번’ 속성은 각 학생의 유일한 식별자로 사용된다.
문제 2. WHERE 조건 처리
[emp 테이블]
| id | name |
|---|---|
| 1001 | 김철수 |
| 1002 | 홍길동 |
| 1004 | 강감찬 |
| 1008 | 이순신 |
[sal 테이블]
| id | incentives |
|---|---|
| 1002 | 300 |
| 1004 | 300 |
| 1008 | 1000 |
| 1009 | 500 |
[보기]
1
2
3
SELECT name, incentives
FROM emp, sal
WHERE emp.id = sal.id and incentives >= 500
더보기
[정답]
| name | incentives |
|---|---|
| 이순신 | 1000 |
[풀이]
1
2
SELECT name, incentives
FROM emp, sal
emp와 sal 테이블을 조회하여
name과 incentives 컬럼을 출력한다.
1
2
-- 두 조건을 모두 만족하는 행만 남긴다. (AND 조건)
WHERE emp.id = sal.id and incentives >= 500
emp.id = sal.id
| name | incentives |
|---|---|
| 홍길동 | 300 |
| 강감찬 | 300 |
| 이순신 | 1000 |
incentives >= 500
| name | incentives |
|---|---|
| 이순신 | 1000 |
emp.id = sal.id and incentives >= 500
| name | incentives |
|---|---|
| 이순신 | 1000 |
실제 SQL에서는 두 조건이 동시에 적용되지만, 이해를 위해 나누어 설명하였다.
위 쿼리는 내부 조인(INNER JOIN)과 동일한 의미이다.
1
2
3
4
SELECT name, incentives
FROM emp INNER JOIN sal
ON emp.id = sal.id
WHERE incentives >= 500;
| (문법 순서) “셀프웨 구해요” |
문장 실행 순서
1
2
3
4
5
6
5. SELECT
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
6. ORDER BY
참고
1
2
3
4
5
6
7
8
9
INSERT INTO 테이블명(컬럼1, 컬럼2)
VALUES (값1, 값2);
UPDATE 테이블명
SET 컬럼명 = 값
WHERE 조건;
DELETE FROM 테이블명
WHERE 조건;
🤔 만약 WHERE문이 없으면?
UPDATE➔ 테이블의 모든 행(row)의 데이터가 수정된다.
1
2
3
-- 모든 직원 이름이 '홍길동'으로 수정된다
UPDATE emp
SET name = '홍길동';
DELETE➔ 테이블의 모든 행(row)의 데이터가 삭제된다.
1
2
-- emp 테이블 데이터 전부 삭제된다. (테이블 구조는 남음)
DELETE FROM emp;
INSERT는WHERE자체가 없다.
왜냐하면 단순히 행을 추가하는 명령이기 때문이다.
문제 3. 데이터베이스 용어
(1) 릴레이션에서 속성의 개수를 의미
(2) 릴레이션에서 튜플의 개수를 의미
(3) 한 릴레이션의 속성이 다른 릴레이션의 기본키를 참조할 때, 참조하는 속성을 의미
(4) 특정 속성에 대해 입력될 수 있는 값의 유형이나 범위를 의미하고 무결성을 보장하는 기준
[보기]
ㄱ. domain ㄴ. primary ㄷ. degree ㄹ. candidate
ㅁ. cardinality ㅂ. attribute ㅅ. foreign key
더보기
[정답]
(1) ㄷ. degree
(2) ㅁ. cardinality
(3) ㅅ. foreign key
(4) ㄱ. domain
[풀이]
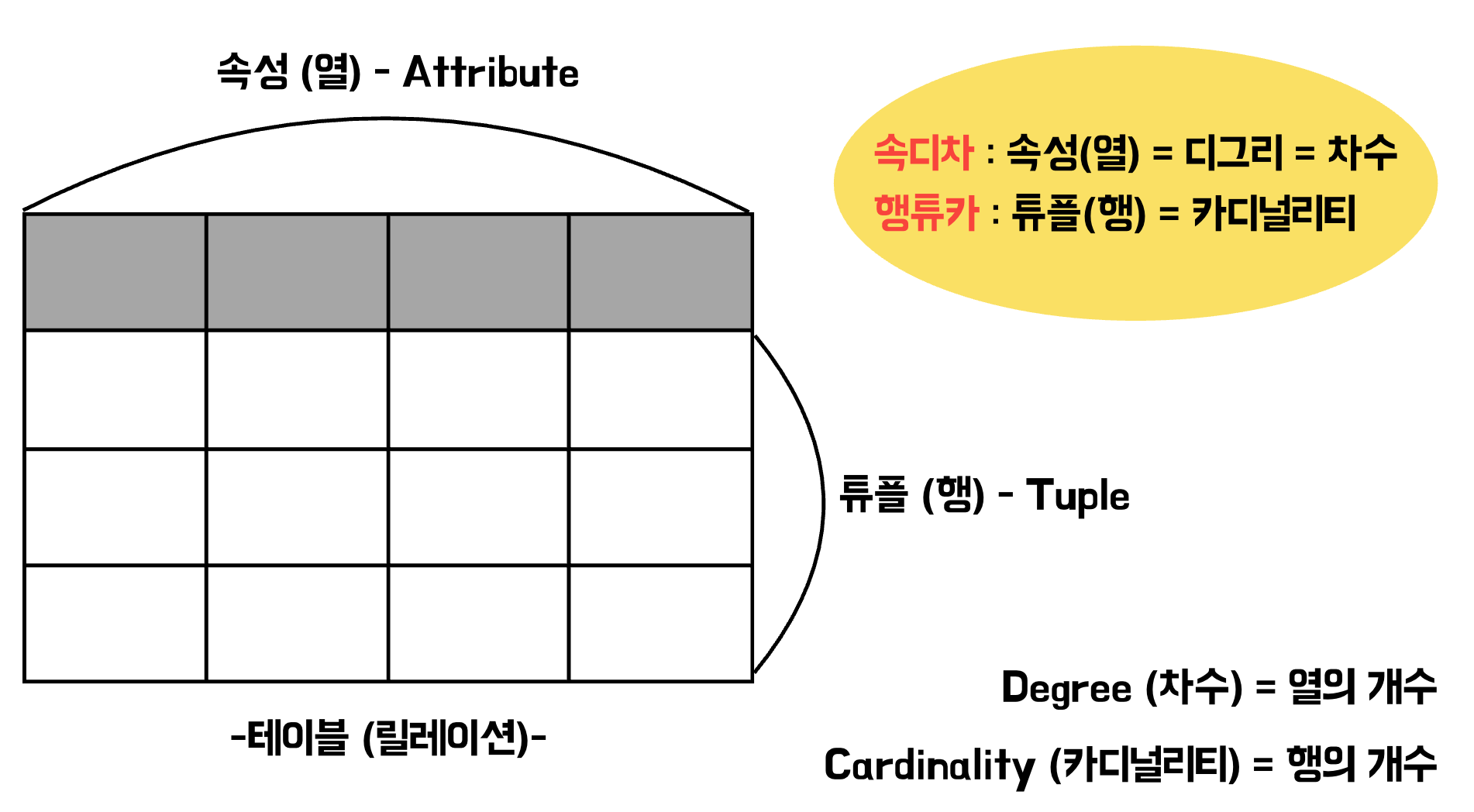
(1) 속성의 개수 : 차수 (degree)
(2) 튜플의 개수 : 카디널리티 (Cardinality)
(3) 한 릴레이션의 속성이 다른 릴레이션의 기본키를 참조할 때, 참조하는 속성을 의미
⟹ 외래키 (Foreign Key)
| Key 종류 |
- 외래키 (
Foreign Key)
다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합 - 후보키 (
Candidate Key)
기본키가 될 수 있는 속성 또는 속성들의 집합
릴레이션에서 튜플을 고유하게 식별할 수 있는 키
모든 튜플에 대해 유일성, 최소성 만족시켜야 함 - 기본키 (
Primary Key)
후보키 중에서 선택된 키로, NULL 값을 가질 수 없으며, 중복된 값도 가질 수 없다.
한 릴레이션에는 하나의 기본키만 존재한다. - 대체키 (
Alternate Key)
후보키 중에서 기본키로 선택되지 못한 후보키 - 슈퍼키 (
Super Key)
하나의 릴레이션에서 튜플을 유일하게 식별할 수 있는 속성 또는 속성들의 집합
유일성은 만족하지만, 최소성은 만족하지 않는다.
(최소성이 만족하지 않으므로, 불필요한 속성이 포함될 수 있다.)ex) 주민등록번호 + 이름 ➔ 이름은 불필요하다.
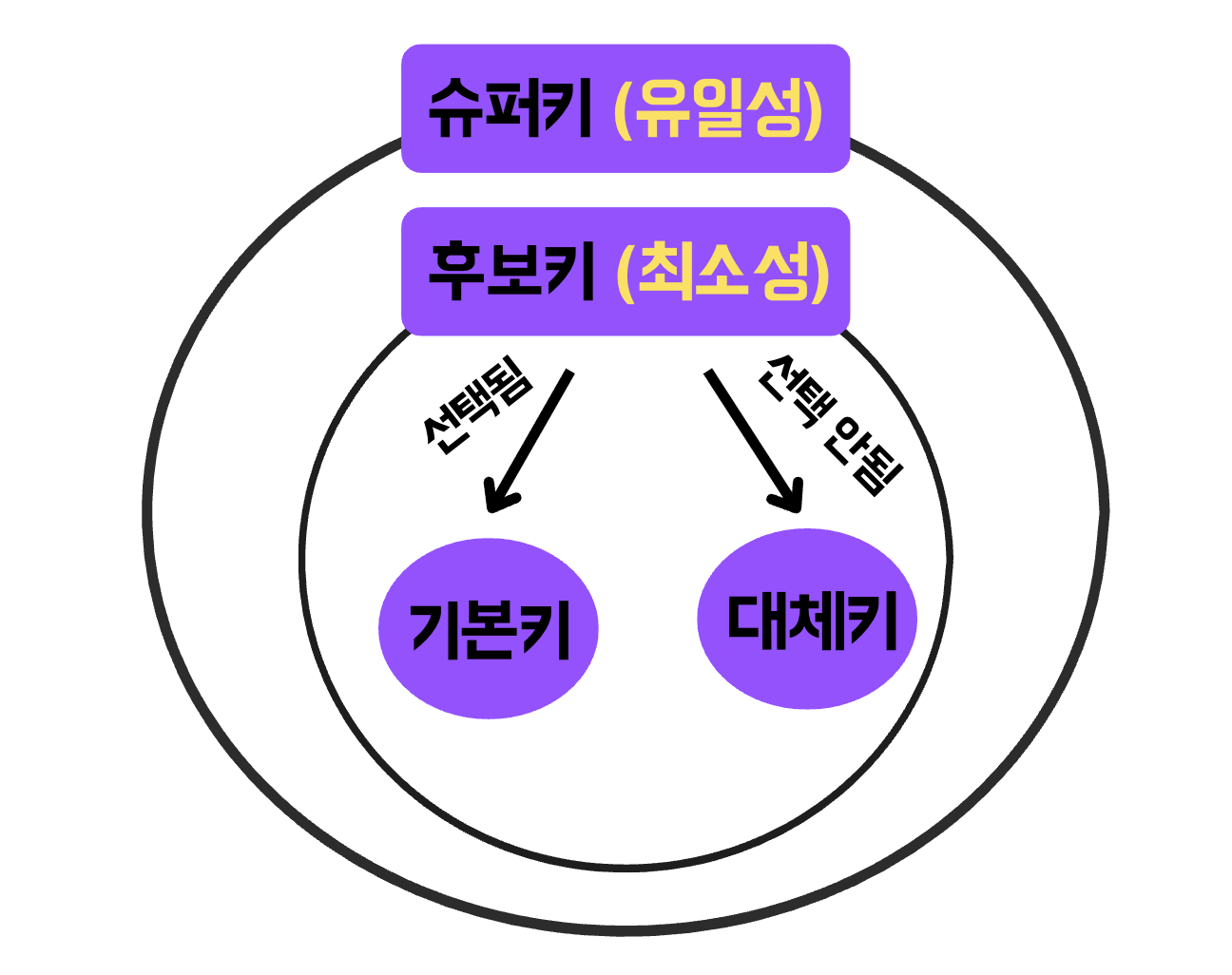
| 🤔 유일성과 최소성은 뭘까? |
- 유일성
각 키가 테이블 내의 모든 튜플을 고유하게 식별할 수 있다.
동일한 값이 중복되면 안된다. - 최소성
꼭 필요한 속성만으로 구성되어야 한다.
불필요한 속성이 없어야 한다.
(4) 특정 속성에 대해 입력될 수 있는 값의 유형이나 범위를 의미하고 무결성을 보장하는 기준
⟹ 도메인 (domain)
도메인 (domain)
속성이 가질 수 있는 값들의 집합으로, 자료형과 허용되는 값의 범위를 지정한다.
| 도메인의 구성 요소 |
- 자료형 (
Data Type) : 정수, 실수, 문자열 등 물리적인 형태 - 값의 범위 (
Value Range) : 예를 들어 ‘성적’ 도메인이라면 0점에서 100점 사이의 값만 허용 - 제약 조건 (
Constraints) : 예를 들어 ‘성별’ 도메인이라면 ‘남’, ‘여’라는 특정 문자만 허용
1
2
3
4
5
6
학번(StudentID)의 도메인 : 정수(integer) 타입이며, 학번 형식(예: 2026001~2026999)을 따르는 값
전공(Major)의 도메인 : 문자열(string) 타입이며, 허용된 학과명 집합
(ex. 컴퓨터공학과, 경영학과, 전자공학과 등)
나이(Age)의 도메인 : 정수(integer) 타입이며, 0 이상 150 이하의 값
| 🤔 왜 도메인을 정의할까? |
도메인을 명확히 정의하면 데이터의 무결성(Integrity)을 유지하기가 매우 쉬워진다.
시스템에 엉뚱한 값(나이가 -20살인 데이터)이 들어오는 것을 데이터베이스 수준에서 원천 차단할 수 있기 때문이다.
2025년 2회 정보처리기사 실기
문제 4. 파일 구조
데이터베이스 물리 설계 시, 레코드에 접근하는 방법은 순차 접근 방법, [ ] 방법, 해싱 방법 등이 있다.
이 중 [ ] 방법은 레코드의 키 값과 포인터를 쌍으로 묶어 저장하며 검색 시 키 값을 기준으로 빠르게 탐색할 수 있도록 설계되어 있다. 이 방식은 검색 속도가 빠르며 <키 값, 포인터> 쌍으로 구성된 자료 구조를 사용하여 해당 키가 가리키는 주소를 통해 원하는 레코드를 직접 찾을 수 있다.
| 접근 방법 | 설명 |
|---|---|
| 순차 접근 | 레코드를 처음부터 하나씩 검사 |
| [ ] 접근 | 키-값 쌍으로 구성되어 빠르게 검색 |
| 해싱 접근 | 해시 함수를 이용해 직접 주소 계산 후 접근 |
더보기
[정답]
인덱스(Index) 또는 색인
[풀이]
데이터베이스의 레코드 접근 방식은 대표적으로 순차 접근, 인덱스 접근, 해싱 접근이 있다.
순차 접근 방식
레코드를 저장된 순서대로 처음부터 끝까지 순차적으로 탐색하는 방식이다.
[특징]
- 구조가 단순하고 구현이 용이함
- 저장 공간 효율이 높음
- 일괄 처리(Batch Processing)에 적합
- 원하는 레코드를 찾기 위해 전체를 탐색해야 하므로 검색 속도가 느림
인덱스(색인) 접근 방식
<키 값, 포인터>로 구성된 인덱스를 이용해 원하는 레코드에 직접 접근하는 방식이다.
- 키(Key) : 검색 기준 값 (예: 학번, 이름)
- 포인터(Pointer) : 실제 데이터의 저장 위치
[특징]
- 인덱스를 통해 빠른 검색 가능
- 데이터 변경 시 인덱스도 함께 갱신해야 하는 오버헤드 발생
- (인덱스를 위한) 별도의 저장 공간 필요
해싱 접근 방식
해시 함수로 키 값을 해시 주소로 변환하여 해당 위치에 직접 접근하는 방식이다.
[특징]
- 주소를 계산해 바로 접근하므로 검색 속도가 가장 빠름 (
평균 O(1)) - 추가 탐색 과정이 없음
- 서로 다른 키가 같은 주소를 갖는 충돌(
Collision) 발생 가능 - 삽입, 삭제, 검색 성능이 전반적으로 우수
| 접근 방법 | 방식 | 특징 |
|---|---|---|
| 순차 (Sequential) | 처음부터 끝까지 순서대로 탐색 | 구현이 단순하지만 검색 속도가 느림 |
| 인덱스 (Index) | <키, 포인터>를 이용한 직접 탐색 | 검색 속도 빠름, 대신 추가 저장 공간 필요 |
| 해싱 (Hashing) | 해시 함수로 주소를 계산 | 가장 빠른 접근, 충돌 발생 가능 |
문제 5. 테이블(릴레이션)의 구성 요소
릴레이션에서 열(Column)을 의미하며 데이터 항목의 속성 또는 특성을 나타낸다.
각 열은 고유한 이름을 가지며 특정 도메인(Domain)에서 정의된 값을 갖는다.
예를 들어 “학생” 릴레이션에서 학번, 이름, 전공 등은 각각 하나의 열이며 이 열들은 학생의 고유한 속성을 나타낸다.
이 개념은 파일 구조에서 필드(Field)에 해당하며 릴레이션에서 행(Row, Tuple)의 구성 요소가 된다.
[보기]
ㄱ. Cardinality ㄴ. Domain ㄷ. Attribute
ㄹ. Degree ㅁ. Schema ㅂ. Tuple
더보기
[정답]
ㄷ. Attribute
[풀이]
문제 6. πTTL(employee) 연산 결과 값
[employee 테이블]
| Index | AGE | TTL |
|---|---|---|
| 1 | 55 | 부장 |
| 2 | 35 | 대리 |
| 3 | 42 | 과장 |
| 4 | 45 | 차장 |
더보기
[정답]
| TTL |
|---|
| 부장 |
| 대리 |
| 과장 |
| 차장 |
[풀이]
프로젝션 연산자 ➔ π
- 원하는 데이터를 수직적으로 도출한다.
- 도출된 릴레이션에 중복된 데이터는 자동 제거된다.
따라서 πTTL(employee) 값은 아래와 같이 출력된다.
| TTL |
|---|
| 부장 |
| 대리 |
| 과장 |
| 차장 |
.jpg)
.jpg)
2025년 3회 정보처리기사 실기
문제 7. CROSS JOIN
[T1 테이블]
| CODE | NAME |
|---|---|
| 3258 | smith |
| 4324 | allen |
| 5432 | scott |
[T2 테이블]
| NO | RULE |
|---|---|
| 12 | s% |
| 32 | %t% |
[실행값]
1
2
3
4
SELECT COUNT(*) CNT
FROM T1 A
CROSS JOIN T2 B
WHERE A.NAME LIKE B.RULE;
더보기
[정답]
4
[풀이]
CROSS JOIN (교차 조인)
두 테이블의 모든 행을 서로 곱하는 카디션 프로덕트를 수행한다.
- T1 (3행) x T2 (2행) = 총 6행 생성
| T1.CODE | T1.NAME | T2.RULE |
|---|---|---|
| 3258 | smith | s% |
| 3258 | smith | %t% |
| 4324 | allen | s% |
| 4324 | allen | %t% |
| 5432 | scott | s% |
| 5432 | scott | %t% |
WHERE절 (LIKE 연산)
생성된 6개의 조합 중 A.NAME LIKE B.RULE 조건을 만족하는 행만 필터링한다.
- smith는
s%와%t%두 가지 규칙에 모두 해당하여 2개의 행이 생성된다. - scott도
s%와%t%두 가지 규칙에 모두 해당하여 2개의 행이 생성된다. - allen은 어떤 규칙에도 해당하지 않는다.
| T1.CODE | T1.NAME | T2.RULE |
|---|---|---|
| 3258 | smith | s% |
| 3258 | smith | %t% |
| 5432 | scott | s% |
| 5432 | scott | %t% |
%는 0개 이상의 문자를 뜻한다.
따라서 COUNT(*)의 결과값은 2 + 2 = 4가 된다.
⟹ COUNT(*) 함수는 조건을 만족하는 전체 행의 개수를 구한다.
CROSS JOIN이란?
두 테이블의 모든 조합을 생성하는 조인이다.
(즉, 가능한 모든 조합을 구하는 연산이다.)
- 결과 집합의 크기는 두 테이블 행 수의 곱과 같다.
- Total Rows =
(Table A의 행 수)x(Table B의 행 수)
➔ 데이터가 조금만 많아져도 결과 값이 기하급수적으로 늘어나 시스템 부하의 원인이 될 수 있음
- Total Rows =
- 특정 컬럼 값이 같아야 한다는 조건(
Join Key)이 없으므로ON절을 사용하지 않는다.
SQL 작성 방식
- 명시적 표현 :
CROSS JOIN키워드를 사용 (권장)
1
2
3
SELECT *
FROM TableA
CROSS JOIN TableB;
- 암시적 표현 : 쉼표(
,)로 테이블을 나열
1
2
SELECT *
FROM TableA, TableB;
문제 8. R % S의 결과
[R 테이블]
| A | B |
|---|---|
| a1 | b1 |
| a2 | b2 |
| a1 | b3 |
[S 테이블]
| B |
|---|
| b1 |
| b3 |
더보기
[정답]
| A |
|---|
| a1 |
[풀이]
디비전 연산자 %
두개의 릴레이션 A와 B가 있을 때,
A % B는 릴레이션 B에 있는 모든 튜플과 대응되는 릴레이션 A의 튜플을 찾는 연산이다.
따라서 R % S 값은 S 테이블에 있는 모든 튜플과 대응되는 R 테이블의 튜플을 구하면 된다.
| A | B |
|---|---|
| a1 | b1 |
| a1 | b3 |
출력은 A의 속성만 출력해주면 된다!! (S 테이블의 B 속성은 제외해야한다.)
| A |
|---|
| a1 |
문제 9. 데이터베이스 용어
ㄱ. 테이블에서 한 행(Row)을 의미하며 하나의 레코드를 구성하는 요소
ㄴ. 실제 데이터가 저장되어 있는 테이블의 내용 전체를 의미하며, 데이터의 상태를 나타낸다.
ㄷ. 테이블에 저장된 행(Row)의 총 개수를 의미한다.
[보기]
스키마(Schema), 속성(Attribute), 튜플(Tuple)
차수(Degree), 인스턴스(Instance), 카디널리티(Cardinality)
더보기
[정답]
ㄱ. 튜플
ㄴ. 인스턴스
ㄷ. 카디널리티
[풀이]
ㄱ. 한 행을 의미 : 튜플
ㄷ. 행의 총 개수 : 카디널리티
ㄴ. 실제 데이터가 저장되어 있는 테이블의 내용 전체를 의미하며, 데이터의 상태를 나타낸다.
⟹ 인스턴스 (Instance)
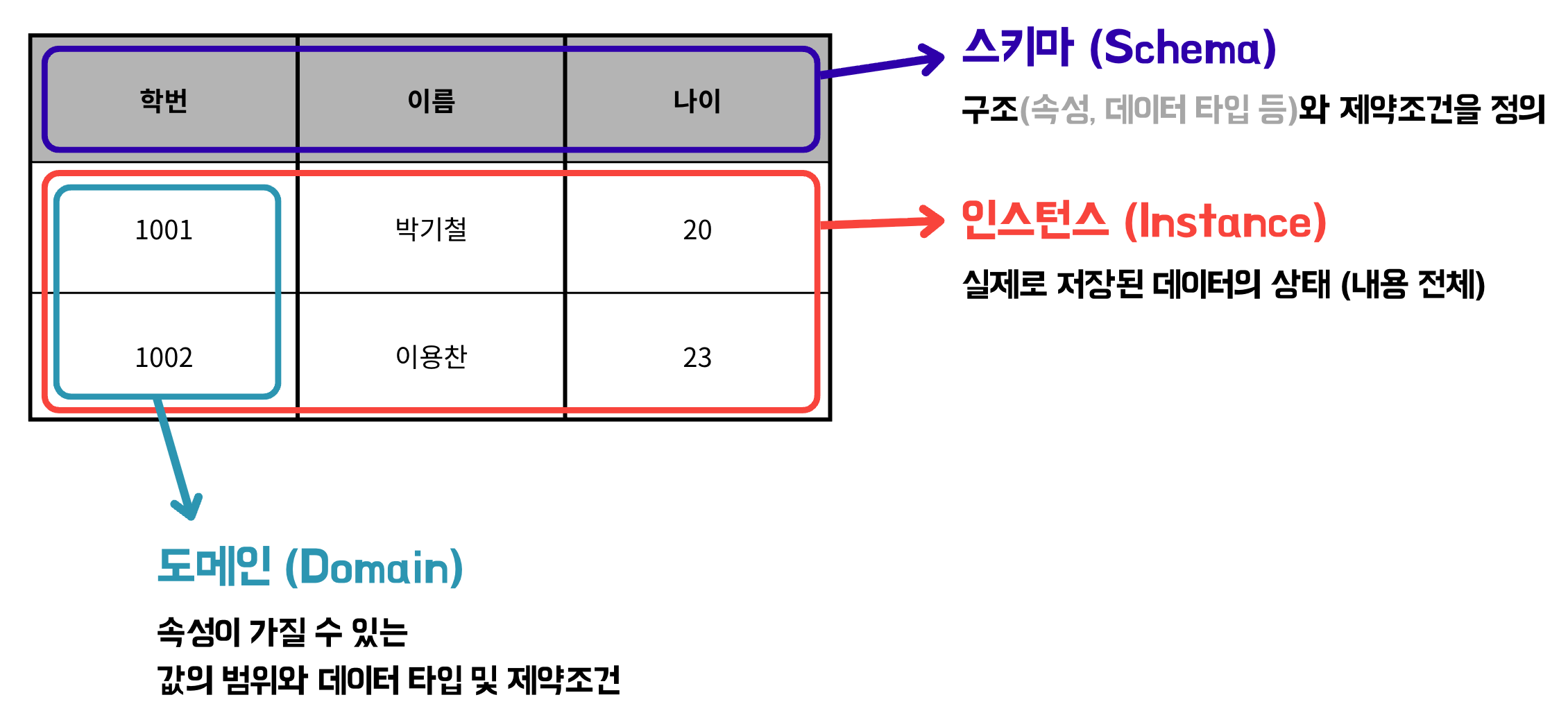
스키마 (Schema) ⟹ 구조
데이터베이스의 구조와 제약조건을 정의한 것으로, 테이블의 구조(속성, 데이터 타입 등)를 의미한다.
인스턴스 (Instance) ⟹ 실제 데이터
정의된 스키마에 따라 데이터베이스에 실제로 저장된 데이터의 상태(내용 전체)를 의미한다.
도메인 (Domain) ⟹ 값의 범위
속성이 가질 수 있는 값의 범위와 데이터 타입 및 제약조건을 의미한다.
- 학번 ➔ 1000 이상의 정수
- 이름 ➔ 문자열 (한글, 영문 등)
- 나이 ➔ 0 ~ 150 사이의 정수
문제 10. OR 조건과 count()의 NULL 처리
[A 테이블]
| col1 | col2 |
|---|---|
| 2 | null |
| 3 | 6 |
| 2 | 3 |
| null | 3 |
| 4 | 5 |
1
2
3
SELECT count(col2)
FROM A
WHERE col1 IN (2, 3) OR col2 IN (3, 5)
더보기
[정답]
4
[풀이]
OR 연산자
WHERE절에서 조건 중 하나 이상 충족하는 행을 반환한다.
1
2
3
4
5
WHERE col1 IN (2, 3) OR col2 IN (3, 5)
-- 두 조건 중 하나라도 TRUE이면 포함
-- 같은 행이 두 조건을 모두 만족해도 1번만 포함
-- ex) (2, 3) 행은 두 조건을 모두 만족하지만 1번만 포함된다.
col1 IN (2, 3)
| col1 | col2 |
|---|---|
| 2 | null |
| 3 | 6 |
| 2 | 3 |
col2 IN (3, 5)
| col1 | col2 |
|---|---|
| 2 | 3 |
| null | 3 |
| 4 | 5 |
col1 IN (2, 3) OR col2 IN (3, 5)- 두 조건 중 하나라도
TRUE이면 포함한다.
- 두 조건 중 하나라도
| col1 | col2 |
|---|---|
| 2 | null |
| 3 | 6 |
| 2 | 3 |
| null | 3 |
| 4 | 5 |
COUNT()
COUNT(col2)는 NULL 값을 세지 않는다.
따라서 (2, NULL) 행은 WHERE절에서는 포함되지만, COUNT 단계에서는 제외된다.
1
SELECT count(col2) -- NULL이 아닌 col2 값만 카운트
| col2 |
|---|
| 6 |
| 3 |
| 3 |
| 5 |
따라서 총 4개가 반환된다.
정리
무결성 제약조건
데이터베이스에 들어있는 데이터의 정확성을 보장하기 위해 부정확한 자료가
데이터베이스 내에 저장되는 것을 방지하기 위한 제약조건이다.
[종류]
- 개체 무결성 제약조건
각 릴레이션의 기본키를 구성하는 속성은 NULL 값이나 중복된 값을 가질 수 없다.
즉, 기본키는 항상 유일하고 비어있을 수 없는 값이어야 한다. - 참조 무결성 제약조건
외래키 값은 NULL이거나 참조하는 릴레이션의 기본키 값과 동일해야한다.
즉, 각 릴레이션은 참조할 수 없는 외래키 값을 가질 수 없다. - 도메인 무결성 제약조건
각 속성들의 값은 정의된 도메인에 속한 값이어야 한다.ex) 나이 속성에 음수 값이나 이상한 값이 들어갈 수 없다.
성별이라는 속성에 ‘남’, ‘여’를 제외한 데이터는 제한되어야 한다. - 고유 무결성 제약조건
특정 속성에 대해 고유한 값을 가지도록 조건이 주어진 경우,
릴레이션의 각 튜플이 가지는 속성 값들은 고유한 값을 가져야 한다.ex) [학생] 릴레이션에서 ‘이름’과 ‘나이’는 서로 같은 값을 가질 수 있지만,
‘학번’의 경우 각 튜플은 서로 다른 값을 가져야 한다. - NULL 무결성 제약조건
릴레이션의 특정 속성 값은 NULL이 될 수 없다.ex) 주민등록번호가 반드시 입력되어야 한다면 NULL 값은 허용되지 않는다.
- 키 무결성 제약조건
각 릴레이션은 최소한 한 개 이상의 키를 가져야 하며, 키는 튜플을 식별할 수 있는 값이어야 한다.ex) [학번] 릴레이션에서 ‘학번’ 속성은 각 학생의 유일한 식별자로 사용된다.
sql 문장 실행 순서
“셀프웨 구해요”
1
2
3
4
5
6
5. SELECT
1. FROM
2. WHERE
3. GROUP BY
4. HAVING
6. ORDER BY
데이터베이스 용어
- 속성 (열) : Attribute
- 튜플 (행) : Tuple
- 속성의 개수 : 차수 (degree)
- 튜플의 개수 : 카디널리티 (cardinality)
스키마 (Schema) ⟹ 구조
데이터베이스의 구조와 제약조건을 정의한 것으로, 테이블의 구조(속성, 데이터 타입 등)를 의미한다.
인스턴스 (Instance) ⟹ 실제 데이터
정의된 스키마에 따라 데이터베이스에 실제로 저장된 데이터의 상태(내용 전체)를 의미한다.
도메인 (Domain) ⟹ 값의 범위
속성이 가질 수 있는 값의 범위와 데이터 타입 및 제약조건을 의미한다.
- 학번 ➔ 1000 이상의 정수
- 이름 ➔ 문자열 (한글, 영문 등)
- 나이 ➔ 0 ~ 150 사이의 정수
Key 종류
- 외래키 (
Foreign Key)
다른 릴레이션의 기본키를 참조하는 속성 또는 속성들의 집합 - 후보키 (
Candidate Key)
기본키가 될 수 있는 속성 또는 속성들의 집합
릴레이션에서 튜플을 고유하게 식별할 수 있는 키
모든 튜플에 대해 유일성, 최소성 만족시켜야 함 - 기본키 (
Primary Key)
후보키 중에서 선택된 키로, NULL 값을 가질 수 없으며, 중복된 값도 가질 수 없다.
한 릴레이션에는 하나의 기본키만 존재한다. - 대체키 (
Alternate Key)
후보키 중에서 기본키로 선택되지 못한 후보키 - 슈퍼키 (
Super Key)
하나의 릴레이션에서 튜플을 유일하게 식별할 수 있는 속성 또는 속성들의 집합
유일성은 만족하지만, 최소성은 만족하지 않는다.
(최소성이 만족하지 않으므로, 불필요한 속성이 포함될 수 있다.)ex) 주민등록번호 + 이름 ➔ 이름은 불필요하다.
| 🤔 유일성과 최소성은 뭘까? |
- 유일성
각 키가 테이블 내의 모든 튜플을 고유하게 식별할 수 있다.
동일한 값이 중복되면 안된다. - 최소성
꼭 필요한 속성만으로 구성되어야 한다.
불필요한 속성이 없어야 한다.
관계 연산자
CROSS JOIN (교차 조인)
두 테이블의 모든 조합을 생성하는 조인이다.
(즉, 가능한 모든 조합을 구하는 연산이다.)
- 결과 집합의 크기는 두 테이블 행 수의 곱과 같다.
- Total Rows =
(Table A의 행 수)x(Table B의 행 수)
➔ 데이터가 조금만 많아져도 결과 값이 기하급수적으로 늘어나 시스템 부하의 원인이 될 수 있음
- Total Rows =
- 특정 컬럼 값이 같아야 한다는 조건(
Join Key)이 없으므로ON절을 사용하지 않는다.
COUNT()
COUNT()는 NULL 값을 세지 않는다.
(값이 존재하는 행의 개수만 계산한다.)
1
2
SELECT COUNT(age) FROM users;
-- age가 NULL인 행은 제외하고 개수를 센다
COUNT(*)은 NULL 여부와 관계없이 전체 행의 개수를 센다.
1
SELECT COUNT(*) FROM users;
파일 구조 - 레코드에 접근하는 방법
순차 접근 방식
레코드를 저장된 순서대로 처음부터 끝까지 순차적으로 탐색하는 방식이다.
[특징]
- 구조가 단순하고 구현이 용이함
- 저장 공간 효율이 높음
- 일괄 처리(Batch Processing)에 적합
- 원하는 레코드를 찾기 위해 전체를 탐색해야 하므로 검색 속도가 느림
인덱스(색인) 접근 방식
<키 값, 포인터>로 구성된 인덱스를 이용해 원하는 레코드에 직접 접근하는 방식이다.
- 키(Key) : 검색 기준 값 (예: 학번, 이름)
- 포인터(Pointer) : 실제 데이터의 저장 위치
[특징]
- 인덱스를 통해 빠른 검색 가능
- 데이터 변경 시 인덱스도 함께 갱신해야 하는 오버헤드 발생
- (인덱스를 위한) 별도의 저장 공간 필요
해싱 접근 방식
해시 함수로 키 값을 해시 주소로 변환하여 해당 위치에 직접 접근하는 방식이다.
[특징]
- 주소를 계산해 바로 접근하므로 검색 속도가 가장 빠름 (
평균 O(1)) - 추가 탐색 과정이 없음
- 서로 다른 키가 같은 주소를 갖는 충돌(
Collision) 발생 가능 - 삽입, 삭제, 검색 성능이 전반적으로 우수
| 접근 방법 | 방식 | 특징 |
|---|---|---|
| 순차 (Sequential) | 처음부터 끝까지 순서대로 탐색 | 구현이 단순하지만 검색 속도가 느림 |
| 인덱스 (Index) | <키, 포인터>를 이용한 직접 탐색 | 검색 속도 빠름, 대신 추가 저장 공간 필요 |
| 해싱 (Hashing) | 해시 함수로 주소를 계산 | 가장 빠른 접근, 충돌 발생 가능 |