[크래프톤정글 1주차 회고] 본격적인 알고리즘 학습
0주차 팀별 프로젝트를 마치고 1주차부터 본격적인 알고리즘 학습을 진행하였습니다.
바로 1주차 과정 컴퓨팅 사고로의 전환인데요.
매 주차별로 알고리즘 문제들이 주어지고 관련 키워드들을 스스로 학습하며 해결해나가는 것입니다.
1주차의 키워드는 정렬, 재귀함수, 완전탐색 등이 있었습니다.
이 중에 재귀함수가 제겐 너무 어려웠는데요.
이해하기 위해서 코드 로직을 따라가며 모든 경우의 수를 작성해보기도 했습니다.
그러고 나니까 흐름이 이해가 되었지만, 다시 재귀의 늪으로 빠지곤 했습니다.
계속 호출하고 호출되고 다시 올라갔다가 내려왔다가 하다보니 헷갈리더라구요.
이번 주차의 어려움을 뽑으라 한다면 재귀함수와 백트래킹 부분이 아닐까 생각합니다.
그럼 1주차 회고도 시작해보겠습니다.
저는 1주차 과정을 진행하면서 스케줄러처럼 현재 진행상황을 체크해줄 수 있는 무언가가 있으면 좋겠다 생각하여 깃허브의 Issues를 활용하여 Todo List처럼 잘 사용했었습니다.
그래서 Issues에 남겨둔 내용을 토대로 회고를 해나가고자 합니다.
저는 Java언어에 익숙해서 Python언어를 사용하며 달랐던 부분에 대해 얘기해보면 좋겠다 생각하여 차이점은 무엇이 있을까?하며 공부하면서 발견했던 부분들이 있었습니다.
파이썬과 자바 문법의 차이점
(참고 : 책 → 자료구조와 함께 배우는 알고리즘 입문(파이썬 편))
함수가 시작하고 종료함에 따라 객체가 생성되거나 소멸하지 않는다.
- 함수 내부에서만 사용하는
지역변수같은 경우엔 사용되고 나면 사라지기 마련인데 파이썬은 소멸하지 않는다.
- 함수 내부에서만 사용하는
- 배열에 서로 다른 자료형 (
int형,float형 등)을 같이 저장할 수 있다.- java의 경우, 서로 다른 자료형이 들어오면 안된다.
- 값이 변경되면 값을 복사하는 것이 아니라 값을 참조하는 객체의 식별 번호가 변경된다.
- 변수를 선언할 때 자료형을 선언하지 않더라도 변수 이름에 값을 대입하기만 하면 그 이름의 변수를 사용할 수 있도록 자료형을 자동으로 선언해준다.
=는 연산자가 아니다.ex) a = (b = 1)=을 오른쪽 결합 or 왼쪽 결합 사용할 수 없다. 이와 같이 사용하게 되면 오류가 발생하게 된다.- java의 경우,
=을 결합 연산자로 사용한다.
- java의 경우,
- 파이썬에서는 값을 비교할 때 등가성(equality)과 동일성(identity)을 사용한다. 등가성 비교는
==동일성 비교는is를 사용한다. 등가성 비교는 좌변과 우변의 값이 같은지 비교, 동일성 비교는 값은 물론 객체의 식별 번호까지 같은지 비교 - 파이썬에서는 매개변수에 실제 인수가 대입된다.
- 인수 전달은 실제 인수인 객체에 대한 참조를 값으로 전달하여 매개변수에 대입되는 방식이다.
이제 알고리즘 문제들을 풀면서 알게된 지식들을 공유하겠습니다.
소수점 자리수 지정
f-string에 콜론(:)을 사용해서 자리수를 지정해주면 됩니다.
1
2
3
#소수점 3자리까지
for percent in students_percent:
print(f"{percent:.3f}%")
문자열 뒤집기
- 반복문
1
2
3
4
5
6
string = "jungle"
reverse_str = ""
for i in string:
reverse_str = i + reverse_str
print(reverse_str) #elgnuj
- 슬라이싱
간격을-1로 설정하고 시작 인덱스, 끝 인덱스를 비워두면 문자열 뒤집기 가능
1
2
string = "jungle"
print(str[::-1]) #elgnuj
reversed내장함수
reversed(string)는 이터레이터를 반환하기 때문에''.join()을 이용해 문자열로 반환
1
2
3
string = "jungle"
reverse_str = ''.join(reversed(string))
print(reverse_str) #elgnuj
문자열 한 글자씩 끊어서 리스트로 변환
1
2
string = "jungle"
print(list(string)) #['j','u', 'n', 'g', 'l', 'e']
list(~)만 해주면 문자열을 각각 한글자씩 잘라서 리스트로 전달해주니까 편리했었다.
퀵 정렬
퀵 정렬은 pivot을 설정하고 그 기준으로 정렬한다.
(pivot을 어떻게 설정하냐에 따라 시간복잡도가 달라진다는 점을 유의)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 이 예제 코드는 pivot을 중간으로 설정
def quick_sort(array):
if len(array) <= 1:
return array
pivot = len(array) // 2
front_arr, pivot_arr, back_arr = [], [], []
for value in array:
if value < array[pivot]:
front_arr.append(value)
elif value > array[pivot]:
back_arr.append(value)
else:
pivot_arr.append(value)
return quick_sort(front_arr) + quick_sort(pivot_arr) + quick_sort(back_arr)
단어 정렬하기 문제 - lambda 함수
단어를 정렬할때의 조건이 2가지가 있다.
- 길이가 짧은 것부터
- 길이가 같으면 사전 순으로 정렬
+) 중복된 단어는 하나만 남기고 제거
1
2
3
4
5
6
7
8
9
10
11
12
13
import sys
N = int(sys.stdin.readline())
input_list = []
for _ in range(N):
input_list.append(sys.stdin.readline().strip("\n"))
set_input = set(input_list) #중복 제거
sorted_list = sorted(set_input, key = lambda x : (len(x), x))
for _ in sorted_list:
print(_)
이 문제를 풀며 이상했던게 있었다.
사용자가 입력한 값을 잘 저장하고 있다고 생각했는데, 아니었던 것이다.
왜냐하면 입력받으면서 \n 개행문자도 함께 append 되고 있었기 때문이다.
따라서 strip()을 활용해 \n 개행문자를 제거 후 append되게 하였다.
Q. 람다(lambda)를 쓴 이유?
key에 한가지의 비교 조건만 들어갈 수 있는데, 위 문제에서는 2가지의 조건을 함께 비교해야하기 때문에 lambda함수를 통해 마치 한가지의 비교조건처럼 묶어서 사용 가능하기 때문이다.
재귀 함수
하나의 함수가 실행되는 동안 다른 함수를 호출 할 수 있고, 심지어 실행되고있는 함수 자신을 다시 호출 할 수 있습니다. 또한 종료 조건이 필수로 작성되어져야합니다.
작성되어져있지않다면 계속 재귀로 프로그램이 돌아가기 때문입니다. 그렇기 때문에 꼭 반드시 빠져나올 수 있는 코드가 작성되어져야합니다.
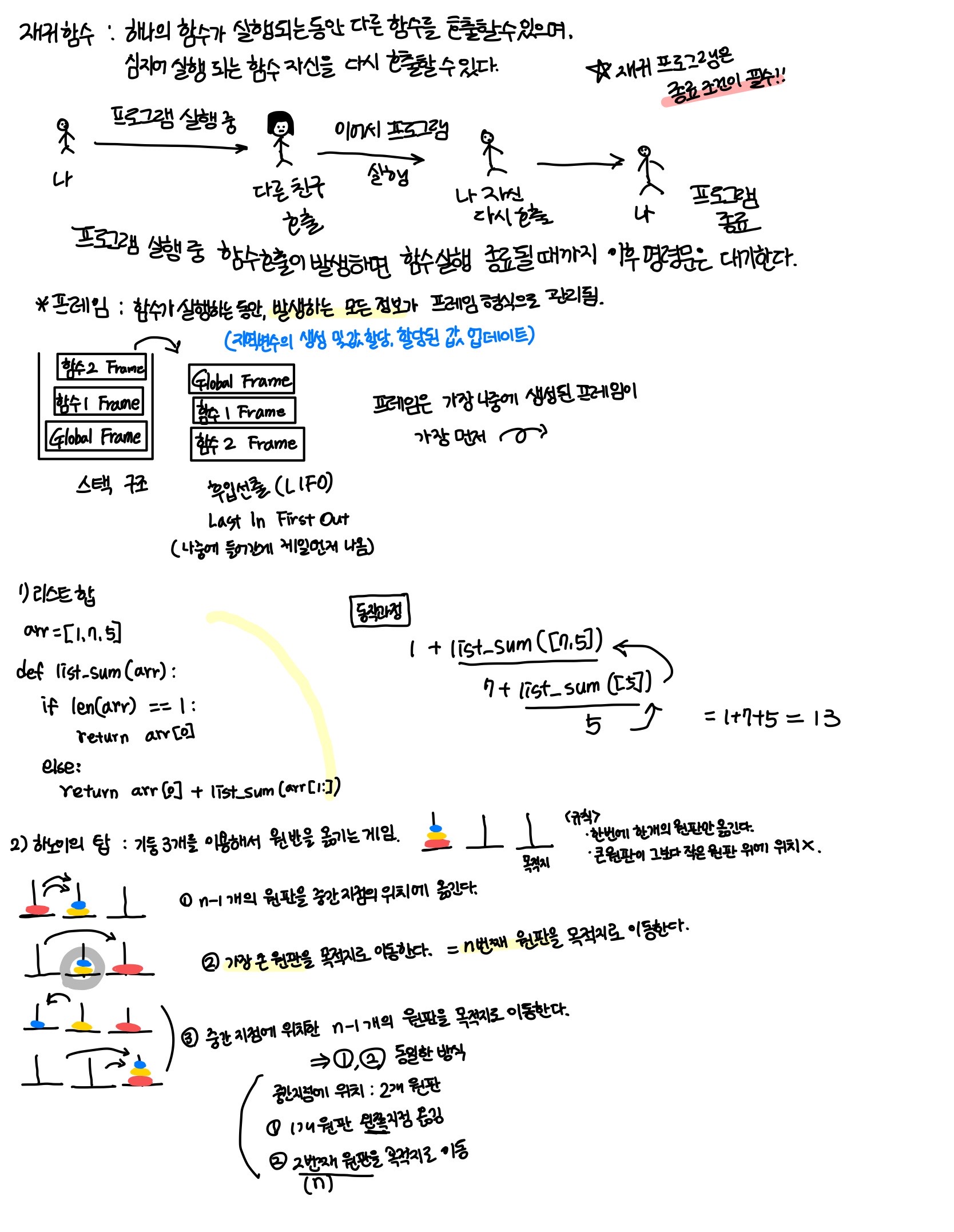
위의 그림과 같이 재귀함수에 대표적으로 하노이 탑 문제가 있습니다.
이 문제를 풀기위해 재귀함수 이해부터 문제 풀기까지 오래걸렸는데요..
그래서 문제 풀이를 짧게나마 작성해보고자 합니다.
하노이 탑
기둥 3개를 이용해 원반을 옮기는 게임
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
import sys
def hanoi(n, first, second, third):
if (n == 1):
print(first, third, sep = " ")
else:
hanoi(n-1, first, third, second)
hanoi(1, first, second, third)
hanoi(n-1, second, first, third)
N = int(sys.stdin.readline())
print(2**N - 1)
if (N <= 20):
hanoi(N, 1, 2, 3)

이 하노이 탑의 규칙이 있다.
- 한번에 한개의 원판만 옮긴다.
- 큰 원판이 그보다 작은 원판 위에 위치하면 안된다.
위 규칙을 따르면 아래와 같은 규칙이 만들어진다.
n-1개의 원판을 중간 지점의 위치에 옮긴다.
1-1)first→second- 가장 큰 원판을 목적지에 옮긴다. =
n번째 원판을 목적지로 이동
2-1)first→third - 중간 지점에 위치한
n-1개의 원판을 목적지로 이동
3-1)second→third
이 규칙을 토대로 하노이 탑 코드를 구현할 수 있다.
브루트 포스(Brute Force)
모든 경우를 다 따지며 해를 찾는 방식
고지식하게 모든 경우의 수를 전부 탐색해보는 것이다.
백트래킹(BackTracking)
불필요한 탐색을 줄이기 위해 가능성이 없는 노드를 더 이상 탐색하지 않는다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
import sys
N, M = map(int, sys.stdin.readline().split())
answer = []
def back():
if len(answer) == M:
print(" ".join(map(str, answer)))
return
for i in range(1, N+1):
if i not in answer:
answer.append(i)
back()
answer.pop()
back()
- 작동 구조
- 탐색 도중에 특정 조건을 만족하는 경우에 대해서만 선택을 시도함 (
append(): 리스트에 값 추가) - 탐색이 끝나면 선택을 취소해 이전 상태로 복구 시킴 (
pop(): 마지막에 있는 값 삭제)
- 탐색 도중에 특정 조건을 만족하는 경우에 대해서만 선택을 시도함 (
1주차 회고
1주차에는 매일 알고리즘 공부하고, 주어진 문제를 풀고 그 과정을 반복했었다.
팀원 두분이랑 어려운 문제를 마주쳤을때, 함께 어떤 방식으로 생각했는지, 어떻게 해야 더 나은 방식일지에 대해 얘기를 많이 나눴었다. 내가 한 방식을 설명할 때도 있었고 반대로 내가 막힌 부분에 대해서 팀원분들께 설명을 들었었다. 그러다보니 내가 생각하지 못했던 부분도 보이게 되고, 시각이 넓혀졌었던 것 같다.
하지만 재귀함수랑 완전탐색 부분은 계속 풀면서도 어려움을 느꼈었다.
백트래킹 구조를 이해하기 위해 N과 M이라는 문제를 추가적으로 풀기도 했었다.
나는 코드를 짤때 그림으로 일단 그려보며 동작 과정을 정리한 뒤에 코드를 작성해나가는데, 아무리 그림을 그려보고 머릿속으로 정리를 해보아도 재귀와 탐색부분은 어려웠다.
이제 2주차에 더 난이도가 올라간 개념들과 알고리즘 문제들을 풀게 될텐데, 그 문제들을 맞서면서 쌓은 경험치들이 1주차에 마지막까지 못푼 문제들을 풀어낼 수 있지않을까? 생각한다.
2주차에도 열심히 배우고, 많이 틀리고, 다양한 시각으로 문제를 바라보자!
그리고 이제 곧 만날 새로운 팀원분들과 많은 소통과 코드적으로 많이 배워야겠다.
깃헙 블로그 문제 해결
원래 잘 돌아가던 깃헙 블로그가 계속 에러가 나는거에요
구글링을 하며 나온 내용들로 여러가지 시도를 해보았지만, 계속 에러가 나서 이제 깃헙 블로그를 못쓰는건가? 했는데, 알고보니 Dependabot 이 친구가 알려줬더라구요. 이 친구가 알려준대로 하니까 다시 블로그가 잘 돌아가서 뿌듯했었습니다.
(답을 모르겠던게 해결되어서 기분이 좋아졌거든요)