Pintos Project 1 : Priority Scheduling
카이스트 핀토스 과제 : Project 1 : Priority Scheduling
두 번째 과제인 Priority Scheduling을 해결해나가보자!
Priority Scheduling
Pintos에서 우선순위 스케줄링(priority scheduling)과 우선순위 기부(priority donation)를 구현해라.
ready_list에 현재 실행 중인 스레드보다 더 높은 우선순위를 가진 스레드가 추가되면,
현재 스레드는 즉시 CPU를 양보하고 그 새로운 스레드에게 넘겨야 한다.
마찬가지로, 스레드들이 lock(락), semaphore(세마포어) 또는 condition variable(조건 변수)을 기다리고 있을 때,
가장 높은 우선순위를 가진 waiting thread(대기하고 있는 스레드)가 가장 먼저 깨어나야 한다.
스레드는 언제든지 자신의 우선순위를 높이거나 낮출 수 있지만,
내린 결과로 인해 자신이 더 이상 가장 높은 우선순위를 가지지 않게 되면, 즉시 CPU를 양보해야 한다.
- 스레드의 우선순위 :
PRI_MIN (0)부터PRI_MAX (63)까지의 범위를 가짐- 숫자가 낮을수록 우선순위도 낮음
- 우선순위
0: 가장 낮은 우선순위 - 우선순위
63: 가장 높은 우선순위
- 스레드의 초기 우선순위는
thread_create()함수의 인수로 전달됨 - 다른 우선순위를 선택할 이유가 없다면,
PRI_DEFULT (31)을 사용해라.
1
2
3
4
// include/threads/thread.h
#define PRI_MIN 0 /* Lowest priority. */
#define PRI_DEFAULT 31 /* Default priority. */
#define PRI_MAX 63 /* Highest priority. */
우선순위 스케줄링에서 발생할 수 있는 문제 중 하나는 priority inversion(우선순위 역전) 이다.
우선순위가 높은 스레드 H, 중간 스레드 M, 낮은 스레드 L이 있다고 가정해보자.
Q. 만약 H스레드가 L스레드를 기다려야 하는 상황이라면? (L이 lock을 쥐고 있어서)
그리고 M스레드가 ready_list에 있는 상태라면?
➔ L 스레드는 M보다 우선순위가 낮기 때문에 CPU를 받지 못하고,
L이 lock을 풀지 못하다보니 H도 계속 기다리게 된다.
(= H는 L이 lock을 놓을 때까지 기다려야 하는데, L은 실행 기회가 없어 lock을 못 놓는다.)
이 문제에 대한 부분적 해결책으로는
L이 lock을 쥐고 있는 동안 L에게 H 자신의 우선순위를 기부(donate)하고,
그 후 L이 lock을 놓으면 (즉 H가 lock을 획득하면), 기부한 우선순위를 회수하는 것이다.
priority donation(우선순위 기부) 기능을 구현해라. |
우선순위 기부가 필요한 모든 다양한 상황을 고려해서 구현해야 한다.
하나의 스레드가 여러 스레드로부터 우선순위를 기부받는 상황도 반드시 처리해야한다.
“중첩된 우선순위 기부(nested donation)도 처리해야 한다”
만약 H가 M이 가진 lock을 기다리고 있고,
M은 L이 가진 lock을 기다리는 상황이라면?
➔ M과 L 모두 H의 우선순위로 상승해야한다.
필요한 경우, 중첩 우선순위 기부의 깊이에 대해 최대 8단계 정도의 합리적인 제한을 둘 수 있다.
lock에 대해서는 반드시 우선순위 기부(priority donation)를 구현해야 함
lock 이외의 Pintos 동기화 도구(예: 세마포어, 조건 변수 등)에 대해서는 우선순위 기부 구현 안해도 됨
우선순위 스케줄링(priority scheduling)은 모든 경우에 대해 반드시 구현해야 함
| 스레드가 자신의 우선순위를 검사하고 수정할 수 있게 해주는 함수들을 구현해라. |
이 함수들의 뼈대는 이미 thread/thread.c에 제공되어있다.
아래와 같이 thread_set_priority(), thread_get_priority() 함수들을 구현해야한다!
1
2
3
4
5
/* Sets the current thread's priority to NEW_PRIORITY. */
void thread_set_priority(int new_priority)
{
thread_current()->priority = new_priority;
}
이 함수는 현재 스레드의 우선순위를 new_priority로 설정한다.
만약 이 변경으로 인해 현재 스레드가 더 이상 가장 높은 우선순위를 가지지 않게 된다면,
즉시 CPU를 다른 더 높은 우선순위 스레드에게 양보(yield)해야 한다.
1
2
3
4
5
/* Returns the current thread's priority. */
int thread_get_priority(void)
{
return thread_current()->priority;
}
이 함수는 현재 스레드의 우선순위를 반환한다.
만약 우선순위 기부(priority donation)가 발생한 상황이라면,
더 높은 (기부된) 우선순위를 반환한다.
한 스레드가 다른 스레드의 우선순위를 직접 수정할 수 있도록 하는 인터페이스는 구현하지 않아도 된다.
우선순위 스케줄러는 이후 프로젝트에서 사용되지 않는다.
과제에 들어가기에 앞서 알아두어야 할 내용
FCFS (First-Come, First-Served) = FIFO
비선점형 스케줄링 기법 중 하나이다.
도착한 순서대로 프로세스를 처리해주는 가장 간단한 스케줄링 알고리즘이다.
프로세스가 queue에 도착한 순서대로 CPU를 할당받아 실행한다.
Convoy Effect(호위 효과)가 발생할 수 있다.
긴 작업이 먼저 도착하면 뒤에 있는 짧은 작업들이 오랫동안 대기하게 되어 평균 대기 시간 길어질 수 있다.
응답시간이 불명확하다.
라운드 로빈(RR, Round Robin) 스케줄링
선점형 스케줄링 기법 중 하나이다.
각 프로세스에게 동일한 시간 할당량을 부여한다.
프로세스가 할당된 시간동안만 CPU를 사용한 후, 다음 프로세스로 전환된다.
따라서 프로세스 각자 공평하게 CPU 시간을 분배받을 수 있도록 보장해준다.
장점으로는 동일한 시간 할당량을 부여받기 때문에 특정 프로세스가 CPU를 독점하지 못한다.
단점으로는 잦은 context switch가 발생할 수 있어서 시스템 오버헤드가 증가할 수 있다.
긴 실행 시간을 필요로 하는 프로세스는 여러 번 CPU를 할당받아야 하므로, 처리 시간이 길어질 수 있다.
목표 - 우선순위 스케줄링 (Priority Scheduling)
ready_list에 새로 추가된thread의 우선순위가 현재 CPU를 점유 중인thread의 우선순위 보다 높으면,
기존thread를 밀어내고 CPU를 점유시킨다.lock,semaphore,condition variable을 사용하여 대기하고 있는 스레드가 여러 개인 경우,
우선순위가 가장 높은thread가 가장 먼저 깨어나야 한다.
ready_list에 스레드를 삽입할 때, 각 우선순위(priority)에 따라 삽입(push)해야한다.
즉 priority가 높은 스레드가 맨 앞부분에 위치하도록 정렬시켜야한다. (내림차순)
본격적으로 코드를 뜯어보며 현재 코드의 전반적인 흐름 파악하기
Pintos의 현재 스케줄링 방식이 어떻게 동작하는지 분석해보자!
thread_unblock(struct thread *t) 함수
1
2
3
4
5
6
7
void thread_unblock(struct thread *t)
{
//...
list_push_back(&ready_list, &t->elem);
t->status = THREAD_READY;
intr_set_level(old_level);
}
BLOCKED상태의 thread를READY상태로 전환하고ready_list의 뒤쪽에 추가한다.
thread_yield(void) 함수
1
2
3
4
5
6
7
8
9
10
/* Yields the CPU. The current thread is not put to sleep and
may be scheduled again immediately at the scheduler's whim. */
void thread_yield(void)
{
//...
if (curr != idle_thread)
list_push_back(&ready_list, &curr->elem);
do_schedule(THREAD_READY);
//...
}
- 현재 스레드가 자발적으로 CPU를 양보할 때 호출되는 함수
- 자신의 상태를 READY로 바꾸고 다시 실행되기 위해
ready_list뒤쪽에 추가됨
현재 Pintos는 ready_lsit를 FIFO 큐로 사용하는 Round-Robin 스케줄러이며,
스레드들은 자신이 양보하거나 unblock이 되었을때 큐의 뒤에 추가되고
항상 큐의 앞에 있는 스레드가 CPU를 점유한다.
do_schedule()함수 속에 schedule()함수를 호출하고 있다.
schedule()함수의 일부 코드를 보았을때, next_thread_to_run()함수를 통해
다음 실행할 스레드를 가져온다.
1
2
3
4
5
6
7
static void
schedule(void)
{
struct thread *curr = running_thread();
struct thread *next = next_thread_to_run(); // 다음 실행할 스레드 가져옴
//...
}
1
2
3
4
5
6
7
8
static struct thread *
next_thread_to_run(void)
{
if (list_empty(&ready_list))
return idle_thread;
else
return list_entry(list_pop_front(&ready_list), struct thread, elem);
}
ready_list가 비어있는지 확인- 비어있다면? CPU를 그냥 냅둘 순 없으므로
idle_thread를 실행함
- 비어있다면? CPU를 그냥 냅둘 순 없으므로
ready_list에 thread가 있다면?- 가장 앞(
front)에 있는 thread를 꺼내서 실행함 ➔list_pop_front()
- 가장 앞(
최종 정리
스케줄링 방식 : Round-Robin (RR)
list_push_back()+list_pop_front()= FIFO 동작
다음에 실행할 스레드를ready_list의 앞에서 꺼내 반환함
ready_list가 비었을땐,idle_thread를 실행함
Q. Round-Robin 스케줄 방식으로 돌아가는걸 어떻게 알 수 있냐?
동일한 시간(time slice)를 할당받아서 공평하게 실행된다.
아래 코드를 보면 알 수 있듯이,
각 스레드는 4 tick 만큼 CPU를 점유한 뒤에 intr_yield_on_return()을 통해
다른 READY 스레드에게 양보하게 된다.
1
2
3
4
5
6
7
8
// threads/thread.c
// 인터럽트가 끝난 후에 자동으로 현재 스레드가 CPU를 yield(양보)하게 됨
void thread_tick(void)
{
//...
if (++thread_ticks >= TIME_SLICE)
intr_yield_on_return();
}
1
2
// threads/thread.c
#define TIME_SLICE 4 /* # of timer ticks to give each thread. */
구현 아이디어
ready_list를 FIFO 큐로 쓰지 않고,
thread의 우선순위(priority)에 따라 정렬된 순서로 관리하자!
즉 ready_list에 삽입할 때 우선순위(priority) 순으로 정렬한다.
기존 list_push_back() 함수가 아니라, list_insert_ordered()함수를 활용하여 변경!
thread_unblock()하고, ready_list에 삽입될 때 우선순위 정렬 삽입해야한다.
또한 thread_yield() 양보하고 ready_list에 삽입될 때도 우선순위 정렬 적용해야함!
실제 구현해보기
thread_create() 함수 수정
현재 실행 중인 스레드(thread_current())보다 새로 생성한 스레드 t의 우선순위가 더 높다면,
현재 스레드가 CPU를 계속 점유하면 안된다.
그러므로 thread_yield()를 통해 즉시 양보하고, 스케줄러가 더 높은 우선순위의 스레드를 실행할 수 있도록 한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
tid_t thread_create(const char *name, int priority,
thread_func *function, void *aux)
{
struct thread *t;
tid_t tid;
ASSERT(function != NULL);
/* Allocate thread. */
t = palloc_get_page(PAL_ZERO);
if (t == NULL)
return TID_ERROR;
/* Initialize thread. */
init_thread(t, name, priority);
tid = t->tid = allocate_tid();
/* Call the kernel_thread if it scheduled.
* Note) rdi is 1st argument, and rsi is 2nd argument. */
t->tf.rip = (uintptr_t)kernel_thread;
t->tf.R.rdi = (uint64_t)function;
t->tf.R.rsi = (uint64_t)aux;
t->tf.ds = SEL_KDSEG;
t->tf.es = SEL_KDSEG;
t->tf.ss = SEL_KDSEG;
t->tf.cs = SEL_KCSEG;
t->tf.eflags = FLAG_IF;
/* Add to run queue. */
thread_unblock(t);
// 추가한 부분
// 현재 스레드가 새로 만든 스레드보다 우선순위가 낮으면? 양보(yield)하도록
if (t->priority > thread_current()->priority)
thread_yield();
return tid;
}
ready_list를 우선순위 기준으로 정렬
먼저 우선순위를 비교하는 함수를 작성해주어야한다.
➔ 우선순위가 높은 thread가 먼저 오도록 비교하는 함수이다.
1
2
// include/threads/thread.h
bool thread_priority_compare(const struct list_elem *a, const struct list_elem *b, void *aux);
1
2
3
4
5
6
7
8
// thread/thread.c
bool thread_priority_compare(const struct list_elem *a, const struct list_elem *b, void *aux UNUSED)
{
struct thread *thread_a = list_entry(a, struct thread, elem);
struct thread *thread_b = list_entry(b, struct thread, elem);
return thread_a->priority > thread_b->priority;
}
thread_unblock() 함수 수정
list_push_back() ➔ list_insert_ordered() 함수로 변경
우선순위 정렬된 ready_list에 삽입함
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// thread/thread.c
void thread_unblock(struct thread *t)
{
enum intr_level old_level;
ASSERT(is_thread(t));
old_level = intr_disable();
ASSERT(t->status == THREAD_BLOCKED);
// 우선순위 정렬된 ready_list에 삽입 - 변경한 코드
list_insert_ordered(&ready_list, &t->elem, thread_priority_compare, NULL);
t->status = THREAD_READY;
intr_set_level(old_level);
}
thread_yield() 함수 수정
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
// thread/thread.c
void thread_yield(void)
{
struct thread *curr = thread_current();
enum intr_level old_level;
ASSERT(!intr_context());
old_level = intr_disable();
// list_insert_ordered()로 변경
if (curr != idle_thread)
list_insert_ordered(&ready_list, &curr->elem, thread_priority_compare, NULL);
do_schedule(THREAD_READY);
intr_set_level(old_level);
}
현재 실행 중인 스레드의 우선순위 변경하는 함수 수정 - thread_set_priority(int new_priority)
우선순위 기반 스케줄링에선 항상 우선순위가 높은 스레드가 먼저 실행되어야한다.
현재 실행 중인 스레드의 우선순위를 낮췄을 경우에
ready_list에 더 높은 우선순위가 있다면?
즉시 CPU를 양보해야 공정한 스케줄링이 된다. ➔ 그래서 thread_yield()를 호출한다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
void thread_set_priority(int new_priority)
{
enum intr_level old_level = intr_disable(); // 인터럽트 비활성화 (= 임계 구역 보호)
thread_current()->priority = new_priority; // 현재 스레드의 우선순위 변경
if (!list_empty(&ready_list))
{
struct thread *top_ready = list_entry(list_front(&ready_list), struct thread, elem);
if (thread_current()->priority < top_ready->priority)
thread_yield();
}
intr_set_level(old_level); // 인터럽트 원상 복구
}
또한 인터럽트 비활성화를 해주었다. 그 이유로는
- 타이머 인터럽트 : 스레드가 실행 중일 때, 인터럽트가 발생하면 다른 애가
ready_list에 접근 가능 - 여러 스레드가 동시에 커널 함수를 호출해
ready_list를 접근 가능
인터럽트 비활성화를 해줌으로써 ready_list는 오직 하나의 흐름에서만 접근 가능하므로 안전하다.
또한 인터럽트 비활성화를 해주어야하는데 그 이유는
동시에 접근하면 race condition이 발생할 수 있다.
그래서 intr_disable()로 인터럽트를 꺼서 임계 구역 보호를 해준다.
1
2
3
4
5
6
7
8
static struct thread *
next_thread_to_run(void)
{
if (list_empty(&ready_list))
return idle_thread;
else
return list_entry(list_pop_front(&ready_list), struct thread, elem);
}
아까 위에서 보았던 next_thread_to_run()이 함수는 그대로 사용 가능하다.
정렬된 리스트에서 list_pop_front()해주기 때문에 우선순위가 가장 높은 스레드가 실행되게 된다.
마무리
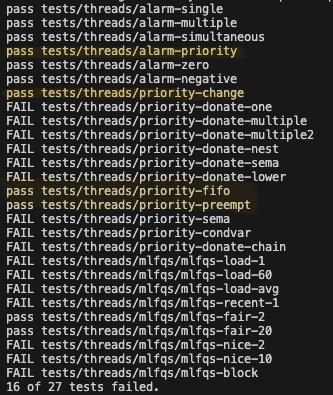
테스트 코드 4개 통과함.
➔ alarm-priority, priority-change, priority-fifo, priority-preempt